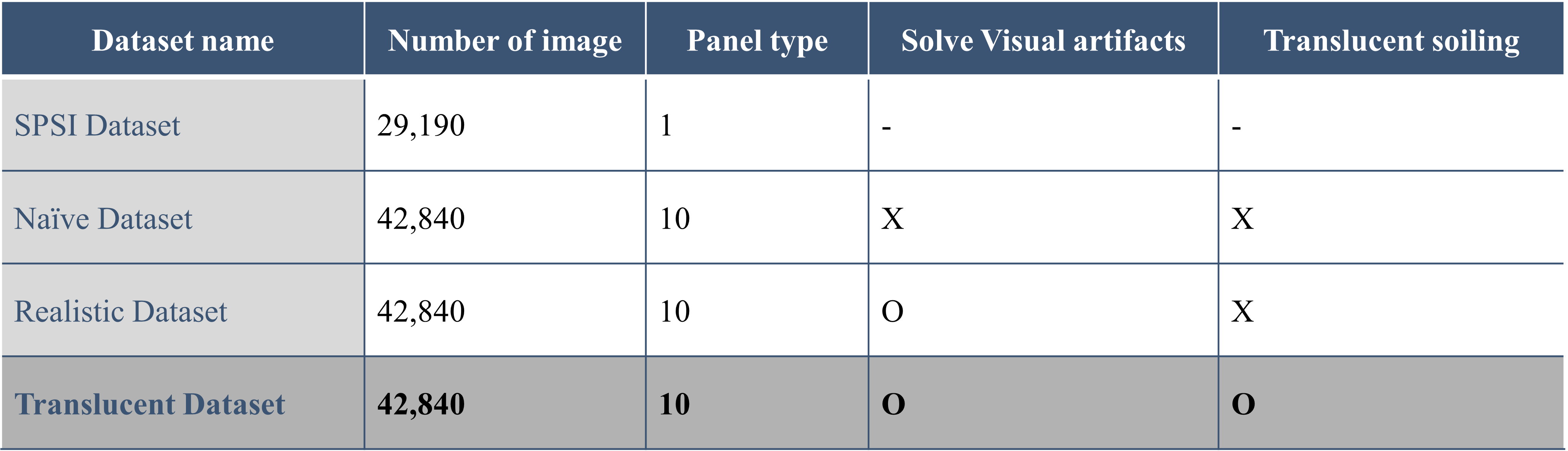
Translucent Dataset
Method
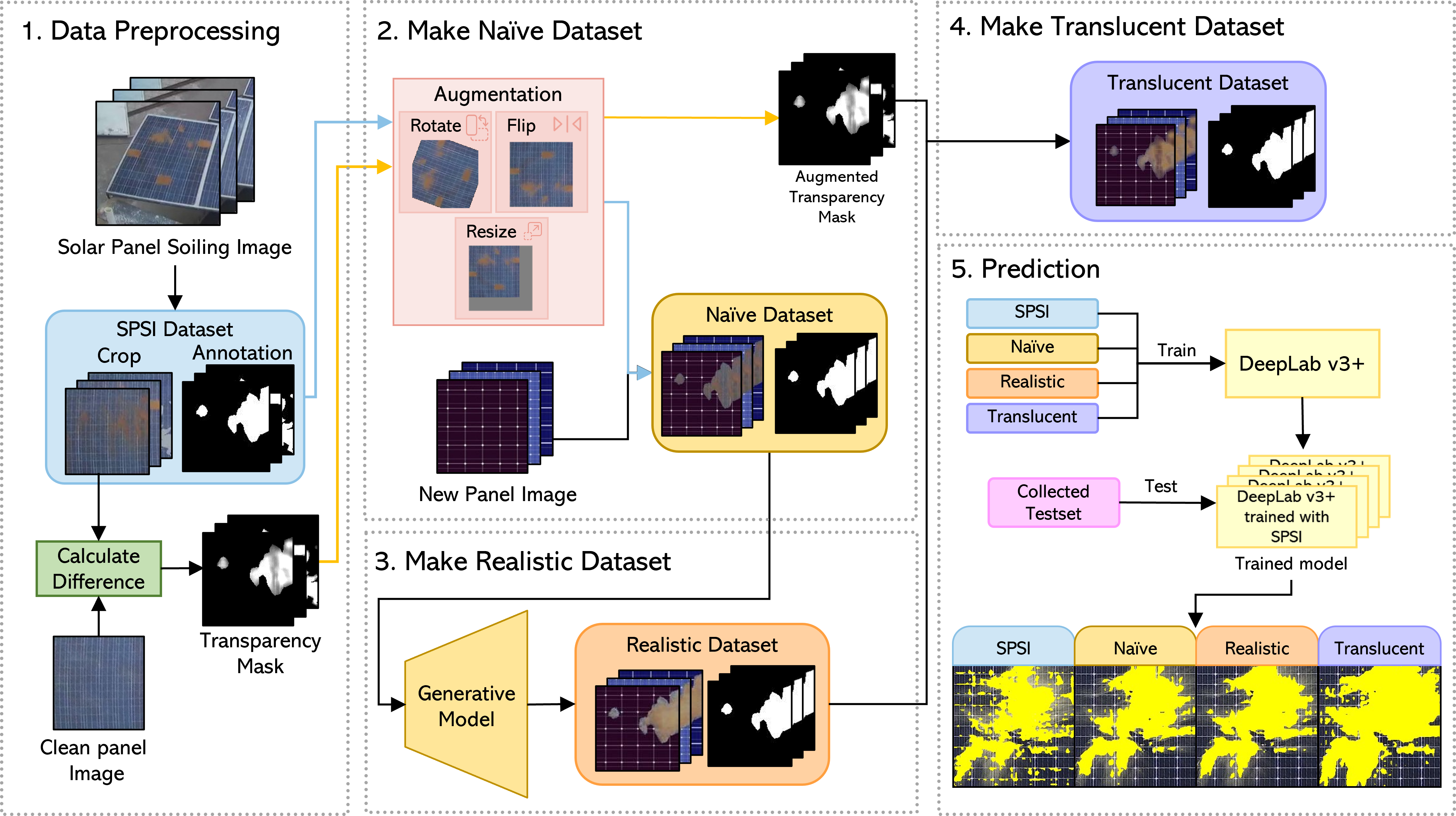
Data Preprocessing
We used 29,190 images (excluding clean panels) from the original SPSI dataset.
We first crop the solar panel region from the images.
We then manually annotate the soiling from each image as the SPSI dataset does not provide the soiling annotation.
Finally, we calculate the RGB distance between the soiling and clean panels.
By using distance, we make transparency masks.
Naive Dataset Generation
We first selected all 84 unique soiling images from the original SPSI dataset.
We then manipulated each image by rotating, vertically and horizontally flipping, and resizing.
Here, all manipulations occur randomly, 50 times per image.
In resizing, we apply a different range from the soiling type.
Finally, we used the Copy-Paste method to copy the soiling part from augmented images of solar panels and pasted them to other types of solar panels.
Realistic Dataset Generation
We trained the Pix2Pix model using the Naive dataset. We exclude the images that have visual artifacts.
We then use all mask images from the Naive dataset as input to the trained generative model to generate new panel soiling images.
he condition(panel type, soiling type) of all images generated by Pix2Pix is the same in Naive Dataset.
Translucent Dataset Generation
We made transparency masks by calculating the RGB distance. The smaller the distance, the more translucent.
We then augmented the transparency mask generated in the Data Preprocessing part.
The manipulation techniques are the same as the augmentation of the make Naive dataset part.
Finally, we create new solar panel soiling images with translucent soiling by applying the corresponding transparency mask to the new panel images from the Realistic dataset.
Prediction
We used the solar panel soiling images we collected as a test set to validate all datasets by using the segmentation model: DeepLab v3+.